Products
Resources

In recent years, large-scale artificial intelligence (AI) models have revolutionised the creative industries, bringing powerful new capabilities to fields ranging from graphic design to music production.
However, this rapid advancement has raised significant concerns among artists and content creators about the unauthorised use of their works. As AI systems become more prevalent, the line between innovation and infringement becomes increasingly blurred.
Other than launching lawsuits to assert their ownership over the content, one emerging tactic some artists have adopted to assert control over their copyrighted material is data poisoning. The practice has sparked a complex ethical debate, pitting the need for innovation against the rights and concerns of individual creators.
This article explores the concept of data poisoning, the methods artists use to execute it, the reasons behind their actions and the broader implications for the AI community and copyright law.
Data poisoning is an adversarial attack technique aimed at undermining the performance of AI models by deliberately introducing corrupt or misleading data into their training datasets.
This method targets the foundation of how AI systems learn, making it distinct from tactics seeking to exploit AI vulnerabilities post-training. Traditional data poisoning can severely compromise an AI’s learning accuracy—subtle alterations in training images, for example, can mislead an AI, drastically reducing its ability to generate outputs or recognise styles.
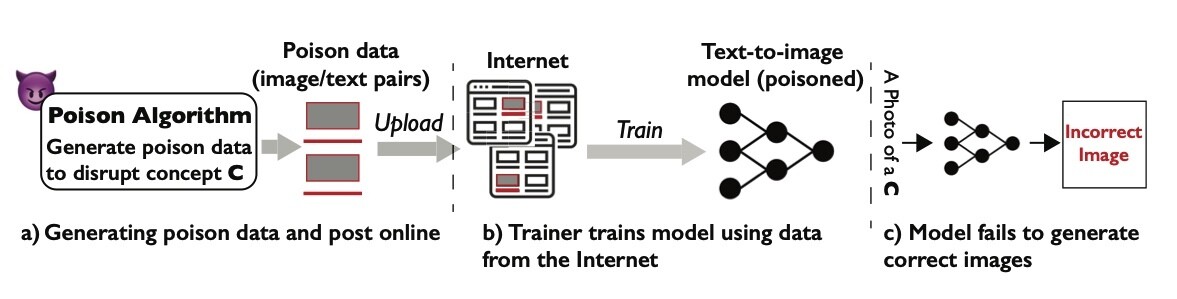
Artists and other creatives have begun to use this technique to protest against AI models’ consumption of their works of art. By contaminating digital versions of their works, these artists aim to degrade the performance of AI models, particularly in how these models interact with the artist’s original works. The goal is to directly impact the AI’s operational efficacy, asserting control over how an artist's content is used without their consent.
Unlike direct hacking attacks or software bugs, data poisoning is usually more insidious and can be harder to detect because it involves the manipulation of the input data itself. It blurs the lines between legitimate data and interference, creating a unique challenge for AI developers who must discern and rectify these alterations to maintain system integrity.
In this instance, it’s not insidious - it’s a direct protest against technology companies’ assumptions that they can use someone’s work without credit, compensation or consent.
Currently, the tools available are specific to artists, photographers and designers - those who create images. These methods subtly alter existing artwork by injecting code into the image (visible to machines but not to the naked eye) to disrupt the models' ability to process the image and make it difficult for them to learn an artist's authentic style. Some of the ways artists can achieve this are:
Subtle alterations to original artwork can significantly interfere with an AI model's ability to process it correctly. This can involve:
An article from Scientific American explains that Nightshade also functions as a “...cloaking tool [that] turns potential training images into “poison” that teaches AI to incorrectly associate fundamental ideas and images.”
Text-to-image systems are essentially giant maps that semantically associate groups of words and images and mislabelling can disrupt the AI's understanding and categorisation of visual art:
Artists and researchers are developing advanced data poisoning tactics as awareness of AI vulnerabilities grows. These include:

Artists engage in data poisoning primarily to address legal, financial and ethical concerns arising from their works being scraped from the internet and incorporated into AI training datasets.
A significant driver for data poisoning is the widespread practice of AI developers scraping vast amounts of content, including copyrighted material, from various online platforms. This material is often used to train algorithms that power commercial AI systems, which generate revenue for tech companies. Artists argue that their work is being commercialised without permission, violating copyright laws designed to protect creators’ intellectual property. There are several ongoing class action lawsuits focused on this - some of which can be found here.
Artists fear that the replication capabilities of AI could lead to a saturation of the market with derivative works. If AI systems can easily mimic an artist’s style, the unique value of their creations could diminish, leading to decreased demand and lower prices for the original works. This impacts their ability to generate an income and also reduces opportunities for future commissions and collaborations, as AI-generated artworks could be seen as cheaper alternatives. In an article on Creativebloq.com, artist Kelly McKernan said, "I saw my income drop significantly in the last year. I can't say for certain how much of that is due to AI, but I feel like at least some of it is.”
Beyond legal and financial issues, many artists hold deep-seated ethical objections to the use of their work by AI systems. They argue that art is an expression of human experience and should not be reduced to data used to train algorithms. This philosophical stance is rooted in a belief in the sanctity of human creativity, a point echoed in this article written by Steve Dennis who says, “Mostly they [artists] want to safeguard what they see as important aspects of human creativity, and be reassured that these will not be undermined or made redundant by potential AI technological storms."
Web scraping for AI training is entangled in complex ethical dilemmas. These concerns span from the legality and fairness of data use to the broader societal implications of how AI models that use this data are deployed. Here’s an expanded look at the major ethical challenges:
The debate around fair use involves determining whether the transformation of data by AI constitutes a legitimate, legal use of copyrighted materials. While some argue that the generation of new, derivative works may fall under fair use, this position is controversial, especially when the data is used to generate profit without compensating the original artists. From a business perspective, this practice can expose companies to legal challenges and reputational damage if perceived as exploiting creative works without fair compensation.
Who owns data once it appears online is a pivotal question in the digital age. While the law may grant copyright to original creators, the pervasive nature of the internet complicates these rights. Using someone's creative output without explicit consent for AI training can lead to disputes over intellectual property rights. Businesses must navigate these waters carefully to avoid legal pitfalls and build systems that respect creator rights, potentially through more transparent data usage policies or consent mechanisms.
Training AI models on data scraped from the web can inadvertently encode existing biases into these systems. This creates ethical, financial and legal risks for businesses as biased algorithms can lead to discriminatory outcomes and violate anti-discrimination laws. Biased AI systems can damage a company’s reputation and erode public trust in its products. Businesses must implement rigorous data curation and testing processes to identify and mitigate these biases.
Data poisoning is a complex challenge for AI systems, with varying degrees of impact depending on the tactics used and the model targeted. Here’s an in-depth analysis of its effectiveness and limitations:
Data poisoning's success in degrading AI performance is not a certainty. The effectiveness depends on several factors, including the scale of the poisoned data introduced, the sophistication of the AI model and the model's ability to detect and mitigate such disruptions. Businesses need to invest in robust AI systems that can identify and rectify corrupted inputs to maintain operational integrity.
For data poisoning to significantly impact an AI model, it often requires a coordinated effort involving multiple artists or data providers. This collective action can be challenging to organise and sustain over time. Businesses should be aware of the potential for such movements to form, especially in industries where copyright infringement concerns are prevalent.
While data poisoning is intended to protect artists’ rights and challenge the ethical practices of AI training, it can have unintended consequences. For example, poisoning could inadvertently damage systems that rely on accurate data to provide essential services, potentially leading to broader disruptions beyond the intended targets. Businesses need to prepare for these risks by implementing more secure data handling and verification processes.
As the debate around AI data usage continues to evolve, there are promising alternatives and regulatory measures that could provide clearer guidance and more ethical practices in AI training. Here’s a detailed exploration of future directions:
One promising alternative is the development of opt-in data systems where artists can voluntarily contribute their work to AI training datasets under clear, fair terms. These platforms could provide compensation and control over how the data is used, ensuring that creators are part of the AI development process more transparently and respectfully. For businesses, adopting these practices could mitigate legal risks and foster a more collaborative relationship with content creators. For example, Stability AI was one of the first companies to sign up for a “Do Not Train” registry.
The need for updated copyright laws specific to AI is becoming increasingly evident as the technology advances. Legislative solutions could include provisions that specifically address the nuances of AI data scraping and usage, providing clearer rules for what constitutes fair use in the context of AI and ensuring adequate compensation for creators. Such laws would protect artists and give businesses a more defined operational framework, reducing uncertainty and promoting ethical practices.
The ongoing dialogue among artists, AI developers, policymakers and legal experts is necessary to address the complex issues surrounding AI governance and data ethics. Engaging in this dialogue can help businesses stay ahead of regulatory changes and align their practices with societal values and expectations.
The use of AI in creative domains is a significant ethical debate centred around the balance between technological advancement and the protection of artistic rights. Data poisoning is one tactic artists can use to assert control over their work, challenging the practices of AI developers and highlighting the need for greater respect and compensation for creative contributions.
These issues underscore the need for better AI governance, regulatory frameworks and more ethical data practices in AI development. Solutions such as opt-in data systems and legislative reforms must be considered to ensure that the advancement of AI technologies does not come at the expense of creators' rights.
Businesses and policymakers must work together to establish practices that support innovation AND respect and uphold the rights of artists and content creators.

In recent years, large-scale artificial intelligence (AI) models have revolutionised the creative industries, bringing powerful new capabilities to fields ranging from graphic design to music production.
However, this rapid advancement has raised significant concerns among artists and content creators about the unauthorised use of their works. As AI systems become more prevalent, the line between innovation and infringement becomes increasingly blurred.
Other than launching lawsuits to assert their ownership over the content, one emerging tactic some artists have adopted to assert control over their copyrighted material is data poisoning. The practice has sparked a complex ethical debate, pitting the need for innovation against the rights and concerns of individual creators.
This article explores the concept of data poisoning, the methods artists use to execute it, the reasons behind their actions and the broader implications for the AI community and copyright law.
Data poisoning is an adversarial attack technique aimed at undermining the performance of AI models by deliberately introducing corrupt or misleading data into their training datasets.
This method targets the foundation of how AI systems learn, making it distinct from tactics seeking to exploit AI vulnerabilities post-training. Traditional data poisoning can severely compromise an AI’s learning accuracy—subtle alterations in training images, for example, can mislead an AI, drastically reducing its ability to generate outputs or recognise styles.
Artists and other creatives have begun to use this technique to protest against AI models’ consumption of their works of art. By contaminating digital versions of their works, these artists aim to degrade the performance of AI models, particularly in how these models interact with the artist’s original works. The goal is to directly impact the AI’s operational efficacy, asserting control over how an artist's content is used without their consent.
Unlike direct hacking attacks or software bugs, data poisoning is usually more insidious and can be harder to detect because it involves the manipulation of the input data itself. It blurs the lines between legitimate data and interference, creating a unique challenge for AI developers who must discern and rectify these alterations to maintain system integrity.
In this instance, it’s not insidious - it’s a direct protest against technology companies’ assumptions that they can use someone’s work without credit, compensation or consent.
Currently, the tools available are specific to artists, photographers and designers - those who create images. These methods subtly alter existing artwork by injecting code into the image (visible to machines but not to the naked eye) to disrupt the models' ability to process the image and make it difficult for them to learn an artist's authentic style. Some of the ways artists can achieve this are:
Subtle alterations to original artwork can significantly interfere with an AI model's ability to process it correctly. This can involve:
An article from Scientific American explains that Nightshade also functions as a “...cloaking tool [that] turns potential training images into “poison” that teaches AI to incorrectly associate fundamental ideas and images.”
Text-to-image systems are essentially giant maps that semantically associate groups of words and images and mislabelling can disrupt the AI's understanding and categorisation of visual art:
Artists and researchers are developing advanced data poisoning tactics as awareness of AI vulnerabilities grows. These include:
Artists engage in data poisoning primarily to address legal, financial and ethical concerns arising from their works being scraped from the internet and incorporated into AI training datasets.
A significant driver for data poisoning is the widespread practice of AI developers scraping vast amounts of content, including copyrighted material, from various online platforms. This material is often used to train algorithms that power commercial AI systems, which generate revenue for tech companies. Artists argue that their work is being commercialised without permission, violating copyright laws designed to protect creators’ intellectual property. There are several ongoing class action lawsuits focused on this - some of which can be found here.
Artists fear that the replication capabilities of AI could lead to a saturation of the market with derivative works. If AI systems can easily mimic an artist’s style, the unique value of their creations could diminish, leading to decreased demand and lower prices for the original works. This impacts their ability to generate an income and also reduces opportunities for future commissions and collaborations, as AI-generated artworks could be seen as cheaper alternatives. In an article on Creativebloq.com, artist Kelly McKernan said, "I saw my income drop significantly in the last year. I can't say for certain how much of that is due to AI, but I feel like at least some of it is.”
Beyond legal and financial issues, many artists hold deep-seated ethical objections to the use of their work by AI systems. They argue that art is an expression of human experience and should not be reduced to data used to train algorithms. This philosophical stance is rooted in a belief in the sanctity of human creativity, a point echoed in this article written by Steve Dennis who says, “Mostly they [artists] want to safeguard what they see as important aspects of human creativity, and be reassured that these will not be undermined or made redundant by potential AI technological storms."
Web scraping for AI training is entangled in complex ethical dilemmas. These concerns span from the legality and fairness of data use to the broader societal implications of how AI models that use this data are deployed. Here’s an expanded look at the major ethical challenges:
The debate around fair use involves determining whether the transformation of data by AI constitutes a legitimate, legal use of copyrighted materials. While some argue that the generation of new, derivative works may fall under fair use, this position is controversial, especially when the data is used to generate profit without compensating the original artists. From a business perspective, this practice can expose companies to legal challenges and reputational damage if perceived as exploiting creative works without fair compensation.
Who owns data once it appears online is a pivotal question in the digital age. While the law may grant copyright to original creators, the pervasive nature of the internet complicates these rights. Using someone's creative output without explicit consent for AI training can lead to disputes over intellectual property rights. Businesses must navigate these waters carefully to avoid legal pitfalls and build systems that respect creator rights, potentially through more transparent data usage policies or consent mechanisms.
Training AI models on data scraped from the web can inadvertently encode existing biases into these systems. This creates ethical, financial and legal risks for businesses as biased algorithms can lead to discriminatory outcomes and violate anti-discrimination laws. Biased AI systems can damage a company’s reputation and erode public trust in its products. Businesses must implement rigorous data curation and testing processes to identify and mitigate these biases.
Data poisoning is a complex challenge for AI systems, with varying degrees of impact depending on the tactics used and the model targeted. Here’s an in-depth analysis of its effectiveness and limitations:
Data poisoning's success in degrading AI performance is not a certainty. The effectiveness depends on several factors, including the scale of the poisoned data introduced, the sophistication of the AI model and the model's ability to detect and mitigate such disruptions. Businesses need to invest in robust AI systems that can identify and rectify corrupted inputs to maintain operational integrity.
For data poisoning to significantly impact an AI model, it often requires a coordinated effort involving multiple artists or data providers. This collective action can be challenging to organise and sustain over time. Businesses should be aware of the potential for such movements to form, especially in industries where copyright infringement concerns are prevalent.
While data poisoning is intended to protect artists’ rights and challenge the ethical practices of AI training, it can have unintended consequences. For example, poisoning could inadvertently damage systems that rely on accurate data to provide essential services, potentially leading to broader disruptions beyond the intended targets. Businesses need to prepare for these risks by implementing more secure data handling and verification processes.
As the debate around AI data usage continues to evolve, there are promising alternatives and regulatory measures that could provide clearer guidance and more ethical practices in AI training. Here’s a detailed exploration of future directions:
One promising alternative is the development of opt-in data systems where artists can voluntarily contribute their work to AI training datasets under clear, fair terms. These platforms could provide compensation and control over how the data is used, ensuring that creators are part of the AI development process more transparently and respectfully. For businesses, adopting these practices could mitigate legal risks and foster a more collaborative relationship with content creators. For example, Stability AI was one of the first companies to sign up for a “Do Not Train” registry.
The need for updated copyright laws specific to AI is becoming increasingly evident as the technology advances. Legislative solutions could include provisions that specifically address the nuances of AI data scraping and usage, providing clearer rules for what constitutes fair use in the context of AI and ensuring adequate compensation for creators. Such laws would protect artists and give businesses a more defined operational framework, reducing uncertainty and promoting ethical practices.
The ongoing dialogue among artists, AI developers, policymakers and legal experts is necessary to address the complex issues surrounding AI governance and data ethics. Engaging in this dialogue can help businesses stay ahead of regulatory changes and align their practices with societal values and expectations.
The use of AI in creative domains is a significant ethical debate centred around the balance between technological advancement and the protection of artistic rights. Data poisoning is one tactic artists can use to assert control over their work, challenging the practices of AI developers and highlighting the need for greater respect and compensation for creative contributions.
These issues underscore the need for better AI governance, regulatory frameworks and more ethical data practices in AI development. Solutions such as opt-in data systems and legislative reforms must be considered to ensure that the advancement of AI technologies does not come at the expense of creators' rights.
Businesses and policymakers must work together to establish practices that support innovation AND respect and uphold the rights of artists and content creators.





